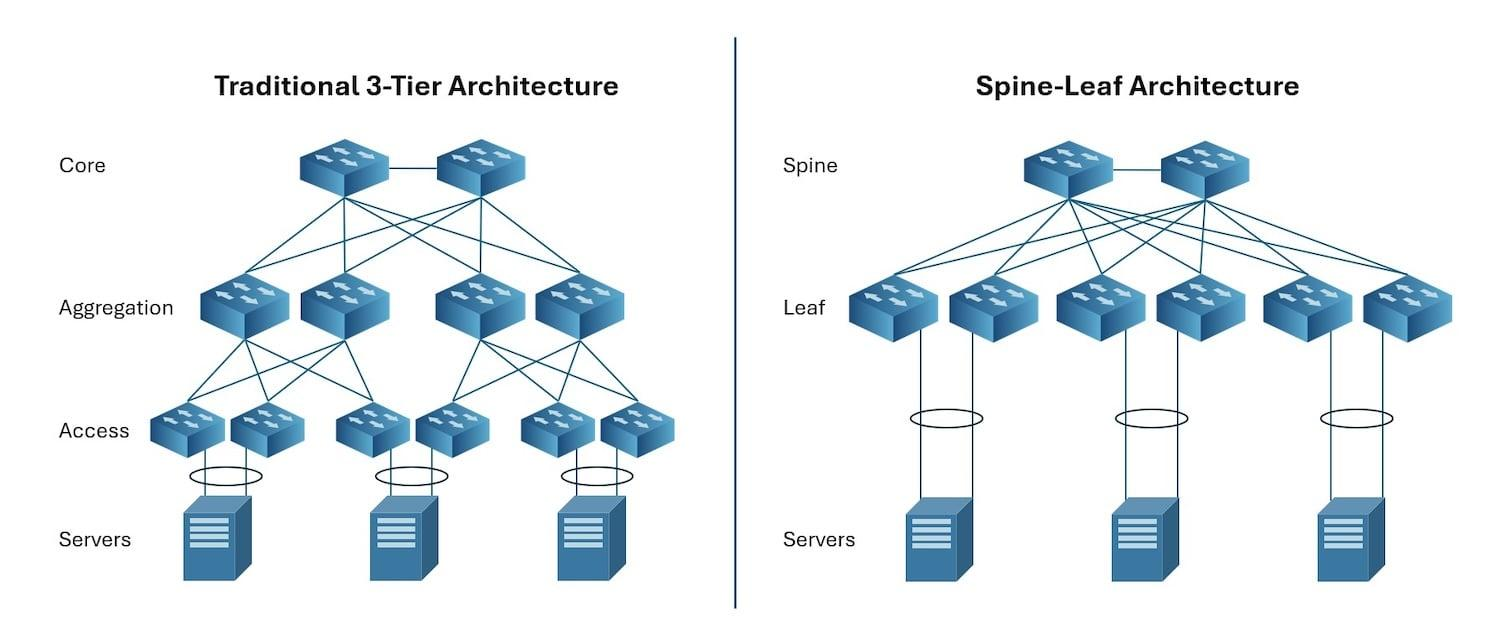
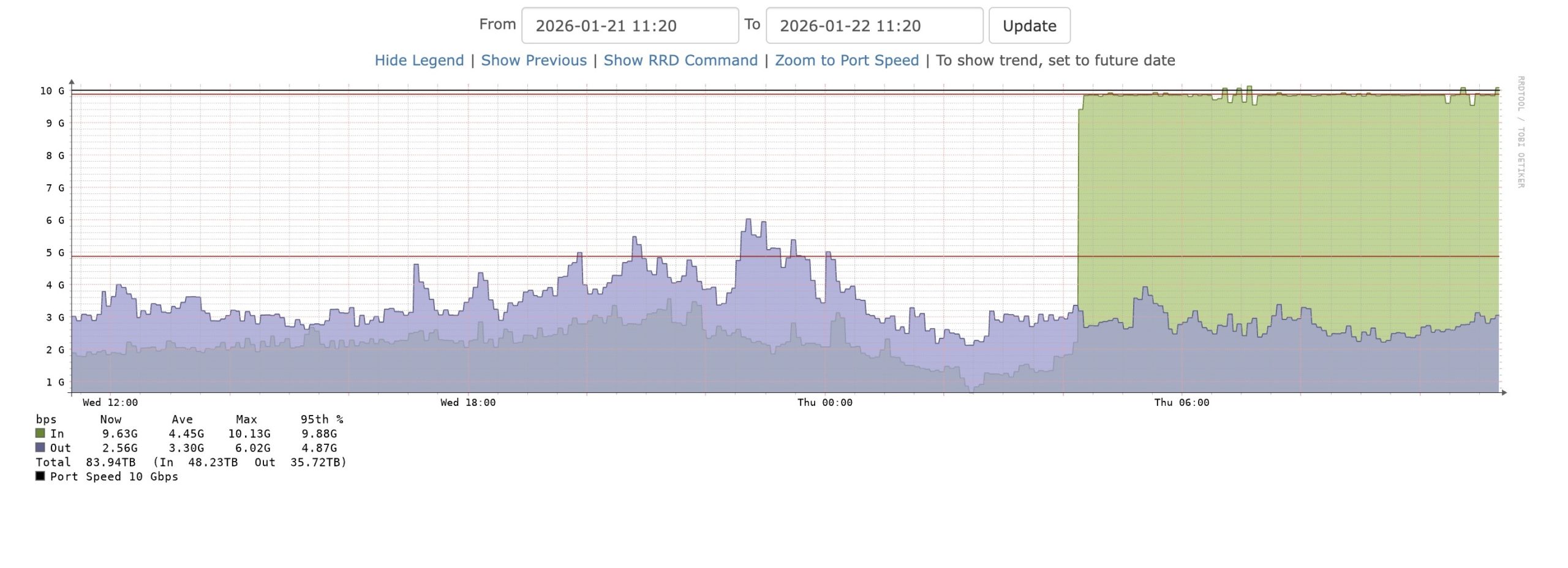
RFC 10005: BGP Community for link capacity
RFC 10005 defines a BGP extended community that lets a router attach link bandwidth information to a route. Another router can use that value when it spreads traffic across multiple BGP paths. RFC 10005 matters because links are not always of the same capacity. This RFC provides routers with a standard way to carry bandwidth … Read more