Mikrotik RouterOS V7 BGP Template $15

The following is a Template for creating a BGP session with both a v6 and a v4 peer in Mikrotik RouterOS v7. It costs $15 for Patreon subscribers or $20 for everyone else.
Packets DownRange
The following is a Template for creating a BGP session with both a v6 and a v4 peer in Mikrotik RouterOS v7. It costs $15 for Patreon subscribers or $20 for everyone else.

In this post, I walk through some key quirks and common pitfalls you might encounter when configuring BGP on MikroTik RouterOS (v6 & v7), Cisco IOS, Juniper Junos, and Arista EOS.

I have created a series of example configurations, a commented PDF, and a Juniper .set for configuring BGP on Juniper routers. This post is available for my Patreon folks here.
This content is for Patreon subscribers of the j2 blog. Please consider becoming a Patreon subscriber for as little as $1 a month. This helps to provide higher quality content, more podcasts, and other goodies on this blog.To view this content, you must be a member of Justin’s Patreon at $15 or more Unlock with … Read more

ISP-specific training focuses on the unique challenges and technologies Internet Service Providers face. Unlike general networking or CompTIA-style certifications, this type of training zeroes in on real-world field scenarios

BFD is a protocol designed to rapidly detect link or path failures between two forwarding engines. It operates independently of routing protocols but works in conjunction with them to improve failure detection and response times.



Podcast: Play in new window | Download (68.6MB)
Border Gateway Protocol (BGP) is a protocol that makes the Capitl I Internet run. It is the fundamental system that Internet Service Providers (ISPs) and large networks use to exchange reachability information and ensure data finds its way across the complex web of networks making up the global Internet.
Border Gateway Protocol (BGP) filtering is critical for securing and optimizing internet routing. Improper BGP configuration can lead to serious issues like route leaks, hijacks, or suboptimal routing. Here are the most effective best practices for BGP filtering: 1. Prefix Filtering Objective: Ensure only authorized prefixes are advertised or accepted. 2. AS-PATH Filtering Objective: Prevent … Read more
This content is for Patreon subscribers of the j2 blog. Please consider becoming a Patreon subscriber for as little as $1 a month. This helps to provide higher quality content, more podcasts, and other goodies on this blog.To view this content, you must be a member of Justin’s Patreon at $1 or more Unlock with … Read more

When BGP (Border Gateway Protocol) misbehaves, the ripple effect can be massive—routes disappear, prefixes flap, and connectivity grinds to a halt. Whether you’re managing a large enterprise edge or an ISP core, knowing how to quickly diagnose BGP issues on Cisco routers is critical. Here’s a hands-on guide to the most useful Cisco IOS BGP … Read more
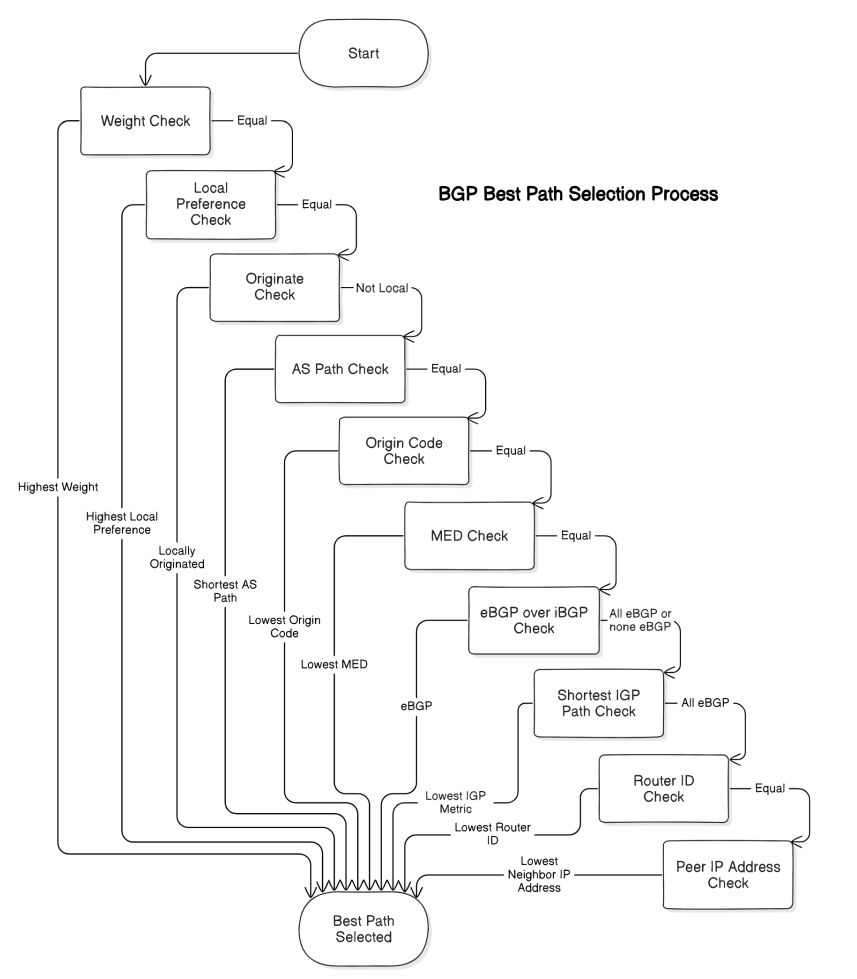
Border Gateway Protocol (BGP) is a protocol that makes the Capital I Internet run. It is the fundamental system that Internet Service Providers (ISPs) and large networks use to exchange reachability information and ensure data finds its way across the complex web of networks making up the global Internet. This post will demystify how BGP … Read more
*) bgp – added input.filter-community;*) bgp – fixed excessive CPU usage;*) bgp – fixed input.accept-community;*) bgp – fixed memory leak on receiving notify and closing session;*) bgp – improved performance on BGP input;