BGP Filtering Best practices for fun and security

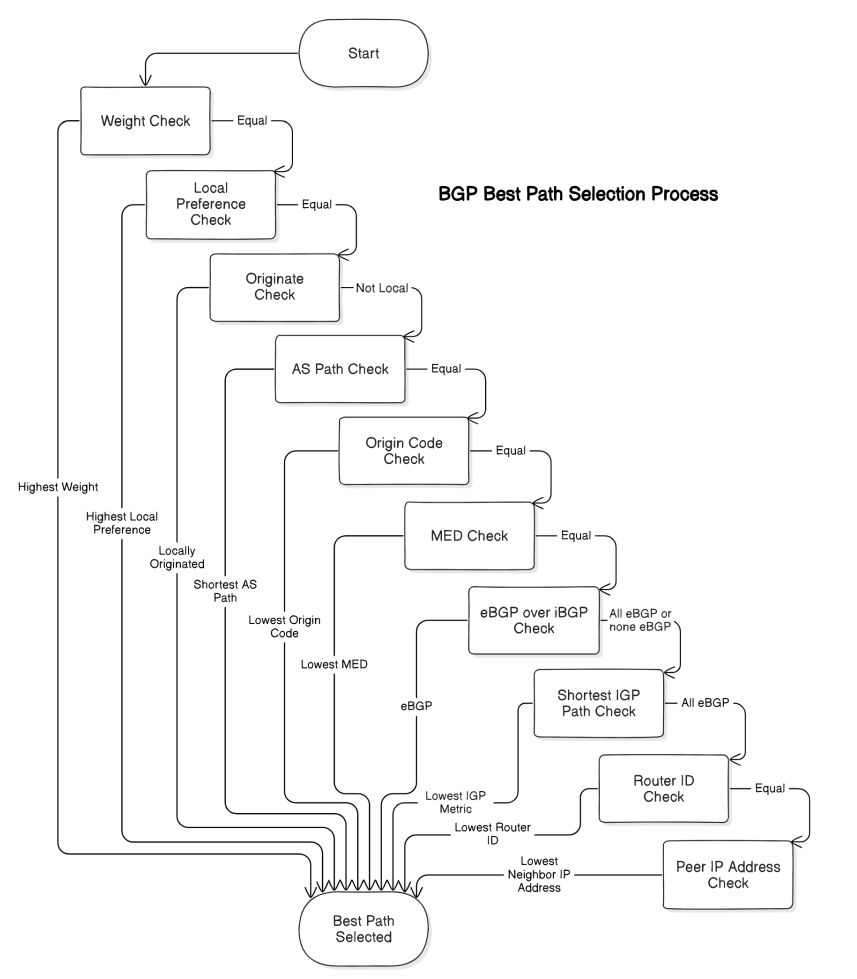
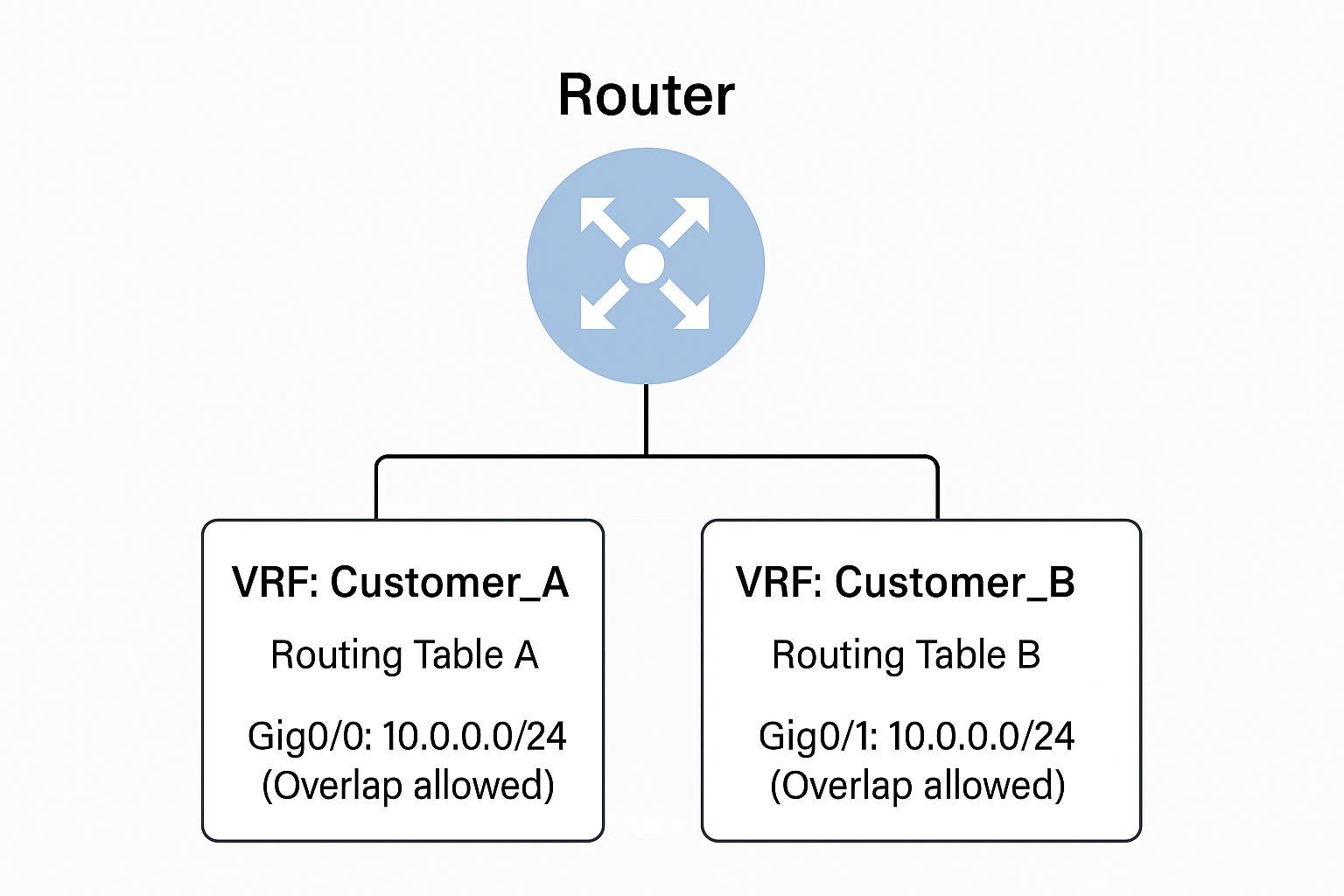
Border Gateway Protocol (BGP) filtering is critical for securing and optimizing internet routing. Improper BGP configuration can lead to serious issues like route leaks, hijacks, or suboptimal routing. Here are the most effective best practices for BGP filtering: 1. Prefix Filtering Objective: Ensure only authorized prefixes are advertised or accepted. 2. AS-PATH Filtering Objective: Prevent … Read more